Linuxマシン1台で完結するCiliumの開発環境
概要
ここ1年ほど機会に恵まれて、Ciliumのアップストリーム開発に参加することができた。
Ciliumはユーザ向けにはもちろん開発者向けにもドキュメントがきちんと整備されてはいるが、情報量が多い英語のドキュメントを読む必要があるので、自分は環境を整えるのに少し手間と時間がかかってしまった。
また、KubernetesクラスタやCIlium自身にデフォルトとは異なる設定を仕込んだ上で、手元でビルドしたCiliumを動かすにあたり、知っておくと楽をできる工夫点をいくつか見つけることができた。
そこで本記事では、Cilium開発/デバッグ環境を手元のLinuxマシンに整備する上で得られた知見を紹介する。
Ciliumとは
Ciliumは、主にKubernetes環境のネットワークを構成するための種々の機能を提供するソフトウェアである。 CNIプラグインとしてPodへのネットワークインターフェースやIPアドレスの割り当てを行うだけでなく、Nodeを跨いだ通信のための経路情報を設定できたり、クラスタから外部NWに出る際のNATを提供していたり、KubernetesのNetworkPolicyやLoadBalancerといったネットワーク系のリソースのバックエンドとしての機能を持っていたりもする。 また、それらの機能を提供するにあたって必要な経路情報等の管理をするコントロールプレーンの役割も果たす。
ソフトウェアとしてのアーキテクチャ
Ciliumのコア部分のソフトウェアとしてのアーキテクチャは下図のようになっている。
 参照:
How is Cilium Tested? - Speaker Deck
参照:
How is Cilium Tested? - Speaker Deck
AgentとOperatorはGoで書かれており、Kubernetes環境においてこれらはPodとして動作する(AgentはDaemonSet)。
そのためログ等もKubernetes自体の枠組みの中で扱うことができる。
この他にL7LBを担うEnvoyや可観測性を提供するHubbleなどのコンポーネントもあるが、これらも同様にGoで書かれており、基本的にはKubernetesの枠組みの中で動く。
Ciliumのコアの部分は主にAgent/Operatorを中心としたこれらのコンポーネントで構成されているのだが、Agentの中のDatapathを扱うeBPFプログラム部分は、プログラムという観点からは少し異質である。
C言語で書かれたこのeBPFプログラム群はバイトコードにビルドされてAgentに組み込まれる。
そしてCiliumがクラスタにインストールされた時にAgentによって各アタッチポイントにロードされ、BPFmapを通してAgentと連携しながら、主にパケット処理を行う。
またCNIプラグインのバイナリはAgentによってNode内にインストールされるが、これ自体がPodとして動くわけではないため、こちらも少し注意が必要である。
LinuxローカルマシンにおけるCilium開発環境の構築
ローカルマシンで完結するCilium開発環境の構築方法として、kind(Kubernetes in Docker)を使う方法がある。 kindはDockerコンテナをKubernetesノードとしてクラスタを構成するツールで、Kubernetesの開発環境を手軽に構築できる。
実際にソースコードからビルドしたCiliumを使ってkindクラスタを立ち上げる一番シンプルな方法は、下のドキュメントのようにCiliumディレクトリ内のMakefileを使うことである。
Development Setup — Cilium 1.17.5 documentation
ただしこの方法ではクラスタやCiliumにデフォルトではない設定を入れて動かす際に、Ciliumリポジトリ内のconfigに変更を加える必要がある。 これは手間がかかる上に、既存のbranchやcommitをそのままの状態でビルドして動かすことができなくなってしまう。 そのため自分は、
という一連の流れを一括で行うスクリプトを、各種configファイルと同じディレクトリに用意して、それを実行するという手段を取っている。 github.com このスクリプト内で上記の3ステップにあたるのは以下の部分である。
// configを指定してkindクラスタ立ち上げ
kind create cluster --image $KIND_IMAGE --config=kind-config.yaml
// kindノード上で動かすためのAgentとOperatorのimageをビルド
make -C "${CILIUM_DIR}" kind-image
// ビルドしたCiliumをクラスタにインストール
cilium install --wait --chart-directory="${CILIUM_DIR}"/install/kubernetes/cilium --values cilium-config.yaml
デバッグプリント
簡単に使えるため、自分はCiliumの開発においてデバッグをする際は、プリントデバッグを利用することが多い。
コード内に埋め込んだデバッグプリントの内容を表示する方法は、コンポーネントによって異なる。
Go部分
Agent/OperatorをはじめとしたKuberenetesのPodとして動くコンポーネントについては、
fmt.Println("test log")
コード中にこのように埋め込んだデバッグプリントについて、Podの出力として出されるため、
kubectl -n kube-system logs -l k8s-app=cilium kubectl -n kube-system logs <pod名>
上記の方法で出力を確認することができる。(app/podの名前のところは適宜変更)
ただしGo部分にもCNIプラグインのバイナリ等、それらとは異なる形で動作するコンポーネントも存在する。 それらについては各々方法を確認する必要がある。
eBPF部分
eBPF部分のコードに埋め込んだデバッグプリントを見る方法は、大きく2つ存在する。 一つ目はbpf_trace_printkを用いてtrace_pipeに出力してそれを観察する方法で、二つ目はBPFmapを通してbpf側のデバッグプリントの内容をcilium-agentに伝えるフレームワークを利用する方法である。
bpf_trace_printk
CiliumのeBPFコード内では、bpf_trace_printkのラッパーであるprintkマクロを利用することができる。
printk("This is a debug-print");
のようにコードに埋め込んだ内容がtrace_pipeに出力されるので、それを読み出すスクリプトを実行することでユーザ空間から確認することができる。 こちらの方法は任意の文字列を埋め込むことが可能であるというメリットがある一方、短時間でたくさんのログを出しすぎるとI/Oが溢れてしまい処理しきれなくなるというデメリットがある。
eBPF部分デバッグ用フレームワーク
Agent内のCLIで実行できるコマンドであるcilium-dbgにはmonitorサブコマンドが備わっており、これはBPFmapに入っているBPFのイベントの内容を表示することができる。
BPFイベントを送るためのデバッグ用関数がeBPFプログラム内に用意されており、これを使うことでデバッグプリントのようなことができる。
cilium_dbg3(ctx, type, value1, value2, value3);
この方法だとI/O溢れのリスクは減る一方、一度に出力できるのは32bitの値3つまでであるため、その表現力はbpf_trace_printkには劣る。 この内容は、
cilium-dbg monitor --verbose -t debug
で見ることができる。
なおここには32bitの値がそのまま出力されるのではなく、このようにtypeごとに値を解釈した結果が表示される。
その他Tips
kindクラスタでBGP Control Plane を動かす
Ciliumには、(K8s用語の)ServiceのアドレスやPod CIDRなどを、cilium-agentに組み込まれたBGPスピーカーを使って広告する、BGP Control Planeという機能が存在する。
これを動かす際には、K8s Node(で動くcilium-agent)とクラスタ外のBGPルータでピアを張りたい場面が多い。
BGPピアを張るためには、お互いのIPアドレスが既知かつそのIPアドレス同士がL3接続性を持っている必要がある。
この要件を素直な方法で実現するためには、cilium-agentとピアを張らせたいBGPルータを、kindノードが属するDockerネットワークに参加させた上で、kindのconfigとBGPルータのconfigを互いに調整して、IPアドレスの整合性を取る必要がある。
このような複数のconfigの調整を不要にする方法として、ソフトウェアBGPルータの設定をcontainerlab経由で行い、さらにcontainerlabから作成したその(BGPルータ等が属する)Dockerネットワークにkindノードを接続するというものがある。 これは、作成したコンテナを別のコンテナのnetwork namespaceにアタッチするcontainerlabの機能を利用して実現できる。
こうすることで、BGPピアリングやそこから得られた経路情報を使ったデータ通信にそのcontainerlab由来のネットワークを利用するならば、関係するIPアドレスや経路情報の設定投入をcontainerlab側に一元化することが可能になる。
この方法はCiliumのリポジトリ内でも紹介されている。
cilium/contrib/containerlab/bgpv2/pod-ip-pool at v1.17.4 · cilium/cilium · GitHub
Dockerのネットワークについて
kind環境のネットワークを操作するためには、Dockerのネットワークについてある程度理解していることが望ましい。 Dockerネットワークの解説をしているとても分かりやすいページがあったので、載せておく。
【連載】世界一わかりみが深いコンテナ & Docker入門 〜 その5:Dockerのネットワークってどうなってるの? 〜 | SIOS Tech. Lab
KVM を使ったVMM の性能ボトルネック解析をして遊んでた話
概要
KVMを使ったVMMがOSを実行する仕組みを詳しく知りたいと思い、ミニマムなVMMとQEMUで小さなOSを動かして、その様子を観察していました。
すると同じブートローダ/OSのバイナリを使っているにも関わらず、ミニマムVMMとQEMUであまりにもOSが実行されるスピードに差があったので、種々のtraceツールを使ったり、QEMU/VMM/OSにデバッグプリントを入れたりしながら、その原因を探っていました。
本記事ではその内容を備忘録的に書き記していこうと思います。
補足
本文の最後に、KVMとVMM(Virtual Machine Manager)について自分なりにまとめた説明を載せています。 これを読んでいる人にとっては知ってる内容がほとんどかなと思いますが、ご興味のある方は読んでみてください。
使用したソフトウェア
ゲストOS
jos : (MITのOS開発の授業で使われているOS) 穴埋め前のコードは公開されているが、完成版は公式には公開されていない。しかし趣味で動くところまで実装して公開してくれている人がいて、それを参考に自分でも途中まで作った。
GitHub - yushoyamaguchi/my_jos at kvmm_lab3 · GitHub
KVMを使ったVMM
kvmm : サイボウズラボユースで自分の2期上の方が開発されていたVMMをforkして利用させてもらった。(ありがとうございます。)
GitHub - yushoyamaguchi/kvmm: kvmm is a type2 hypervisor that uses the Linux Kernel Virtual Machine(KVM). · GitHub
非常にシンプルなコードで、シングルコアのx86のゲストOSを動かせるVMMが実装されている。
流れ
動かしてみた
kvmm上でjosを実行してみたところきちんと動いたのだが、その速度がQEMU上で実行した時よりもかなり遅かった。
(測っていないが、QEMU上だと1秒未満で終わる初期化処理+シェル起動に1分近くかかっていた。)
kvmmの実装はシンプルだが無駄はないはずで、それなのにQEMUとこんなに実行時間に差が出るのは何か大きな原因があると思い、探ってみることにした。
kvmm の実行において時間がかかっている部分の特定
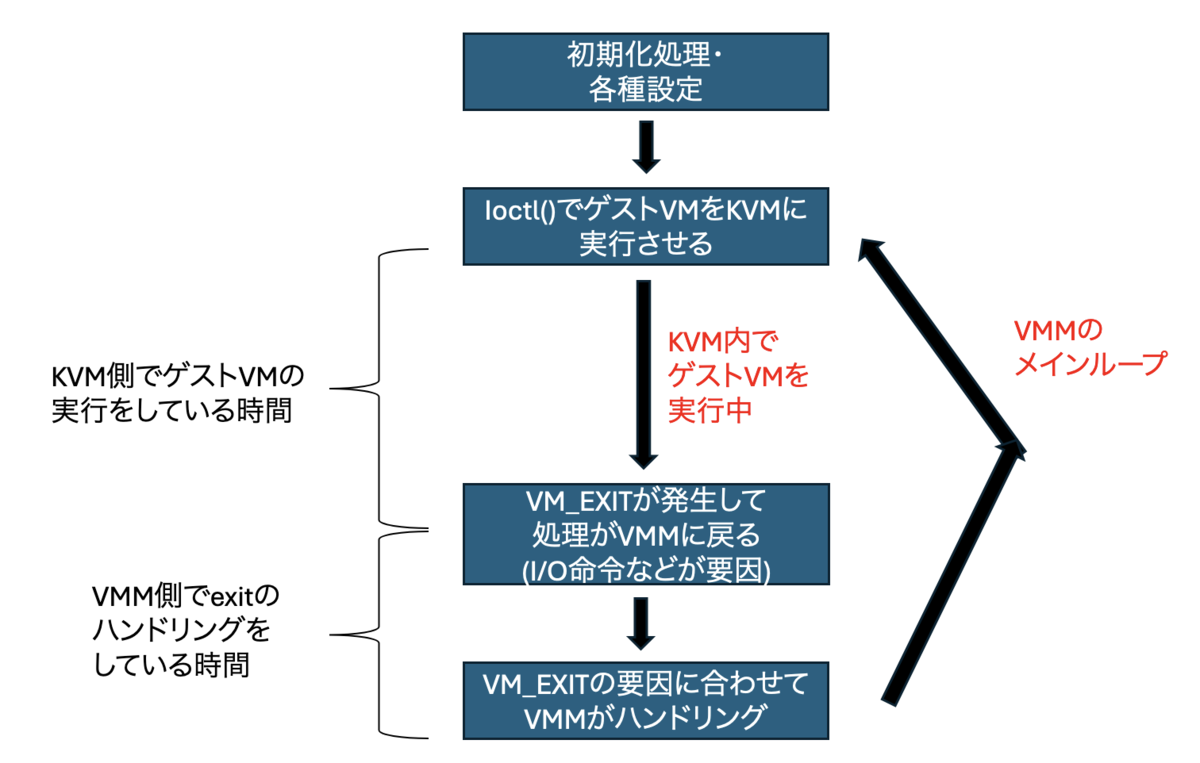
まずは図のVMMの処理のうち、どの部分で時間がかかっているのかを、kvmmにデバッグプリントを入れることで確かめた。

計測の結果、ボトルネックはKVM側の処理であることが分かった。
perfを使って測定
次に、perfコマンドを使ってKVMの何の処理にCPU時間が消費されているのかを調べた。
sudo perf record -a -g -- <kvmmを実行するコマンド>
その結果、VCPU_RUN(ゲストOSの実行)をKVMに指示するためのioctlシステムコールの呼び出し処理にCPU時間が消費されていることが分かった。
しかもそのうちの半分以上の時間は、実際にカーネル内のvcpu_run()を呼び出すまでのシステムコールなどの手続きに使われている様子が見られた。
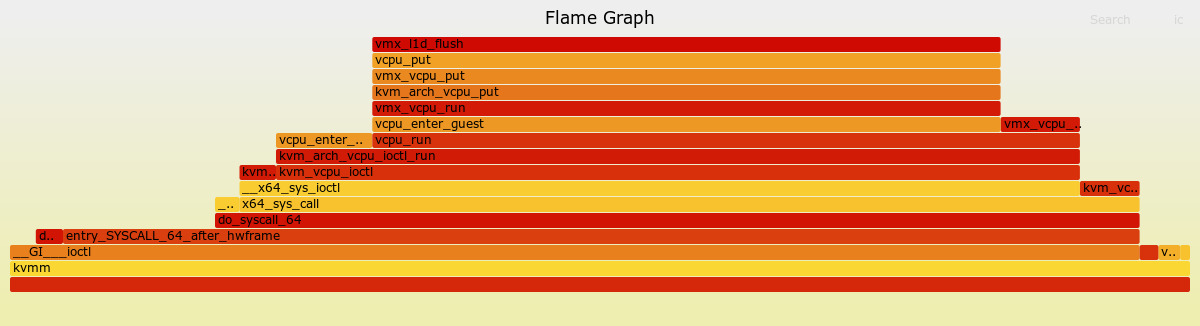
VMexitの原因別の呼び出し要因の確認
ioctlの呼び出しがCPU時間のボトルネックになっているということは、VM_EXITが呼び出される回数が多いことがパフォーマンス低下の原因である可能性が高いと考え、kvmmとQEMUそれぞれでjosを実行している際の、VM_EXITの原因を調べた。
kvmmとQEMUのそれぞれメインループ内に、exitの原因別の回数をカウントするコードと、その結果を出力するコードを追加し、その出力を確かめるという方法で行った。
その結果、EXIT_IO というI/O命令の単位時間あたりの呼び出し回数が、kvmmの方が多いことが分かった。


差がつく原因となっているI/O
どのI/OポートへのI/Oが原因で、EXIT_IOの回数の差が出ているか確認するために、デバッグプリントを追加して確かめたところ、kvmmでは0x84番ポートへのIN命令がI/Oの大半を占めているにも関わらず、QEMUで実行した時には0x84番ポートへのIN命令によるVM_EXITは一度も起きていないことが分かった。
josにおいて0x84番へのIN命令が実行されるのは、
my_jos/kern/console.c at bd0219877d72e556dc1857e06a586b8a1fd7cc05 · yushoyamaguchi/my_jos · GitHub
この関数だけであった。 (どうやら古いハードウェアに対応するためのコードらしい...)
// Stupid I/O delay routine necessitated by historical PC design flaws static void delay(void) { inb(0x84); inb(0x84); inb(0x84); inb(0x84); }
原因特定!
このdelay()関数の呼び出し元を探すと、
my_jos/kern/console.c at bd0219877d72e556dc1857e06a586b8a1fd7cc05 · yushoyamaguchi/my_jos · GitHub
for (i = 0; !(inb(COM1 + COM_LSR) & COM_LSR_TXRDY) && i < 12800; i++) delay();
my_jos/kern/console.c at bd0219877d72e556dc1857e06a586b8a1fd7cc05 · yushoyamaguchi/my_jos · GitHub
for (i = 0; !(inb(0x378+1) & 0x80) && i < 12800; i++) delay();
この2箇所であり、それぞれserial port とparallel portのステータスレジスタの値がセットされるまで、delay()を繰り返すというコードになっている。
disable delay · yushoyamaguchi/my_jos@400d1ce · GitHub
試しにこのdelay()の呼び出しをコメントアウトしてみると、kvmmで動かしても、QEMUの時と同じくらいの体感スピードでゲストのjosを実行することができた。
遅かった原因は、
kvmmではそれらのステータスレジスタへのI/Oのエミュレーションを実装していなかった → delay()が何回も繰り返し呼び出された → 0x84番ポートへのIN命令によってVM_EXITが多発した → VMMのメインループ内で何回もVCPU_RUNをするためのioctlシステムコールが呼び出され、それがボトルネックとなっていた
というものであった。
やはりシステムコール呼び出しのオーバーヘッドはとても大きい...
余談: eBPFを使ったtracing
当初 ここ で0x84番ポートへのI/Oの有無が、(ゲストOSのバイナリが同じなのに)実行するVMMによって異なるということが分かった時、なぜかゲストOSの条件分岐ということを考えなかった。
そしてこれはKVMのバグに違いない! という決めつけをして、KVMの部分のカーネル内の関数をeBPFのkprobeを使って調べまくるという行動に出てしまった。
intel CPUの仮想化支援機構VMXを使っているときに、ゲストのI/O命令をハンドルする関数を特定し、そこから呼び出されるkvm_fast_pio()という関数のport引数を調べた。
https://elixir.bootlin.com/linux/v5.15/source/arch/x86/kvm/vmx/vmx.c#L4911
その結果、QEMUで実行しているときは、VMXの内部で0x84へのIN命令を実行しようとした形跡自体がないと分かり、VMMによる挙動の違いの原因はゲストOSにあると思い直し、原因を特定するに至った。
(その時に使用したeBPFプログラムはこちら)
yama_eBPF/ebpf_flab/trace_kvm_ioport at 6dc3603a31ac03b62caa7ebcca2f7e632bd748b8 · yushoyamaguchi/yama_eBPF · GitHub
おさらい: KVMとVMM(Virtual Machine Manager)
※正しくない記述があれば教えてください!!
KVMはVMを実行するためにLinux Kernelの中に実装されているアクセラレータで、(ホストマシンのCPUの命令セット向けにコンパイルされたものであれば、)CPU自体のエミュレーションを実装することなく、ゲストVMのコードを実行することができます。
KVMの特徴としては、Intel VT-xやAMD-Vなどのハードウェア仮想化支援技術を使っているためパフォーマンスに優れる点や、ioctlという馴染み深いシステムコールを通じてVMに対する設定/操作を行うことができる点が挙げられます。
ただし、KVMはあくまで仮想マシンの実行を支援するための基盤であり、実際にゲストOSを動かすためには、VMM (Virtual Machine Manager) と呼ばれるソフトウェアが必要です。VMMは、ioctlを使用してKVMにゲストVMの設定や初期化を行い、仮想環境を管理します。
KVMでは、ゲストOSが特権命令を実行しようとしたり、I/Oアクセスやページフォルト、特定のレジスタの書き換えが発生した場合、処理を一時停止してVMMに制御を戻します。VMMはこれらのイベントを適切に処理し(例えば、I/O命令であれば対応するハードウェアへのアクセスを行う)、再びKVMに処理を戻してゲストOSの実行を続けさせるという役割も担っています。
VMM(QEMU)とKVMの仕組みについては、これらの記事が大変参考になりました。
より詳しく知りたいという方は、ぜひ参照してください。
QEMUのなかみ(QEMU internals) part1 - るくすの日記 ~ Out_Of_Range ~
KVMのなかみ(KVM internals) - るくすの日記 ~ Out_Of_Range ~
Linuxで動くNICドライバの開発をしている
概要
Linuxで動くe1000eドライバを開発しようとしており、ドライバと紐付けたNICのstateがupになるところまで進めました。
個人的に忙しくなった都合で一旦ここでプロジェクトを止めるため、備忘録としてここまでの作業内容を簡単に書き記し、詰まった点についても文章として残しておこうと思います。
前半部では、NICドライバ実装のために必要な処理のうちパケット送受信以外に関する部分について書いています。
後半部では、ドライバ実装中にLinuxカーネル関連で詰まった箇所とその解決の様子を書いています。
おことわり
実はまだパケットを送受信する部分を作りこめていません。 そのこともあって、ドライバがパケットを送受信する仕組みなどについてはこの記事では一切触れないことにしました。
知りたい方は別の何かを読んでください、すみません。
自分は下記のような記事を読んで理解することができましたので、ご興味のある方はぜひ見てみてください。(すごくわかりやすいです)
MikanOS に NIC ドライバを実装する - 準備編 #自作OS - Qiita
Intel NIC ドライバにおけるパケット送信について - かーねるさんとか
流れ
以前xv6へe1000eドライバを実装し、無事送受信ができることを確認できたので(ソースコード)、次はそのドライバをLinuxで動かそうと思いました。
Linuxではドライバをカーネルモジュールとして組み込むことができるので、カーネルと一緒にビルドする必要がありません。
自分もこの機能を使って自作ドライバを動かす方針にしました。
またLinuxではカーネル側が提供するAPI関数を使うことで、自作のNICドライバとカーネルのネットワークスタックを連携させることもできます。
[前半]:NICドライバ実装に必要な作業
デバイスドライバの実装してカーネルモジュールとして動かす方法は、こちらの記事と書籍を参考にさせていただきました。
組み込みLinuxデバイスドライバの作り方 (1) #Linux - Qiita
Linuxデバイスドライバプログラミング | SBクリエイティブ
insmod/rmmod 時のエントリポイントとなる関数を用意
https://github.com/yushoyamaguchi/yama_driver/blob/debug1/yama_e1000e/netdev.c#L305
https://github.com/yushoyamaguchi/yama_driver/blob/debug1/yama_e1000e/netdev.c#L318
pci_diriver構造体を定義して、ドライバを登録
ドライバを登録する方法は、デバイスの種類によって異なる。
PCIデバイスに関しては、insmod時のエントリポイントとなる関数で、pci_divice登録用の関数を呼び出すことで登録できる。
引数となるのはpci_driver構造体で、ここにこのドライバが取り扱うデバイスのリストや、デバイスの状態変化時に呼び出される関数を定義する。
こうすることで、今実装しているドライバとデバイスを紐づけることができる。
static struct pci_driver yama_e1000_driver = { .name = yama_e1000e_driver_name, //name .id_table = yama_e1000_pci_tbl, //the list which specify the PCI devices supported by the driver. .probe = yama_e1000_probe, //function that is called when the kernel discovers an appropriate PCI device .remove = yama_e1000_remove // function that is called when a matching PCI device is removed from the system };
今回実装したのはこれだけだが、きちんとしたドライバを作るには他にも実装すべき項目はある。
net_deviceとして登録
probe関数内で、デバイスをnet_deviceとして登録する。
struct net_device *netdev = alloc_etherdev(sizeof(struct yama_e1000e_adapter)); if(!netdev){ return -ENOMEM; } netdev->netdev_ops=&yama_e1000e_netdev_ops; // some ops ret=register_netdev(netdev);
alloc_etherdev関数の引数となっているyama_e1000e_adapterという構造体は、ドライバ実装において必要な変数を含むものを自分で定義したものである。
こうすることで、任意の必要な値をprivateデータとしてnet_device構造体の末尾にくっつけて取り扱うことができる。
現時点で自分が定義しているデータは、以下である。
https://github.com/yushoyamaguchi/yama_driver/blob/debug1/yama_e1000e/include/yama_e1000e.h#L33
net_deviceハンドラ関数を用意してハンドラテーブルに登録
static const struct net_device_ops yama_e1000e_netdev_ops = { .ndo_open = yama_e1000e_netdev_open, .ndo_stop = yama_e1000e_netdev_close, .ndo_start_xmit = yama_e1000e_start_xmit, .ndo_set_mac_address = yama_e1000e_set_mac_addr, .ndo_get_stats = yama_e1000e_get_stats, };
下記のような仕様に沿った形で、net_deviceとしての様々な役割をこなす関数を作成し、テーブルに登録する。
https://elixir.bootlin.com/linux/latest/source/include/linux/netdevice.h#L1400
全てを実装することはできないので、とりあえず必要そうな関数だけを登録した。(それでもその中身はまだ完成なのですが...)
パケット送信時に呼び出される関数は、ndo_start_xmit のところに登録する。
割り込みの定義(未動作確認)
受信はパケットが入ってきた時に、割り込み処理として実行されるようにしたい。
そのため以下のように、受信時に呼び出したい関数 yama_e1000e_irq_handler を登録した。
ret=request_irq(adapter->pdev->irq,yama_e1000e_irq_handler,IRQF_SHARED,yama_e1000e_driver_name,adapter);
この関数の第一引数には、該当するirq番号を入れる。
PCIデバイスの場合は、スロットごとにIRQ番号が自動で決められており、OSから教えてもらうことができる。
MMIOレジスタを適切に初期化して、実際にパケットを処理する部分を書いていく(未実装)
上記のように、パケット送受信部の処理を実装する。
ハンドラとスケジューリング
割り込み
割り込みの後半部、Softirq、Tasklet、Work Queue
上記の記事のように、割り込みハンドラ自体の処理を短くすることで、割り込み禁止の時間をを短くする必要がある。
時間的制約のある処理だけをハンドラで行い、残りの処理はよしなにスケジューリングする。
[後半]:Linuxカーネル関連で詰まったところ
insmod時のカーネルクラッシュ
はじめ、insmod時にカーネルがクラッシュする症状が出ていた。
クラッシュ時のメッセージを読むために、
-serial file:path_to/serial.log
上記のオプションをつけて起動したQEMU上でUbuntuを動かして、
ゲストUbuntu上で /etc/default/grub を編集してコンソールの内容をシリアル出力するように変えた上で、ドライバを動かした。
[ 646.160007] genirq: Flags mismatch irq 11. 00000000 (yama_e1000e) vs. 00000080 (uhci_hcd:usb1)
クラッシュ時にこのようにirq番号に関するエラー出力を観測できたので、request_irq関数の第三引数をIRQF_SHAREDに変えることで、カーネルクラッシュが起こらないようにした。
インターフェースのstateがUPにならない問題
動作しているインターフェースを iproute2を利用して見た際は通常、下記の写真のようにstateがUPになっている。

しかし自分が実装したドライバが紐づいているインターフェースをiproute2を使って見たところ、stateがUNKNOWNになっていた。
原因を探るべく、iproute2のnetlinkメッセージを読み取る部分にデバッグプリントを入れて実行してみたところ、netlinkメッセージのoperstateという部分が原因であるように思えた。
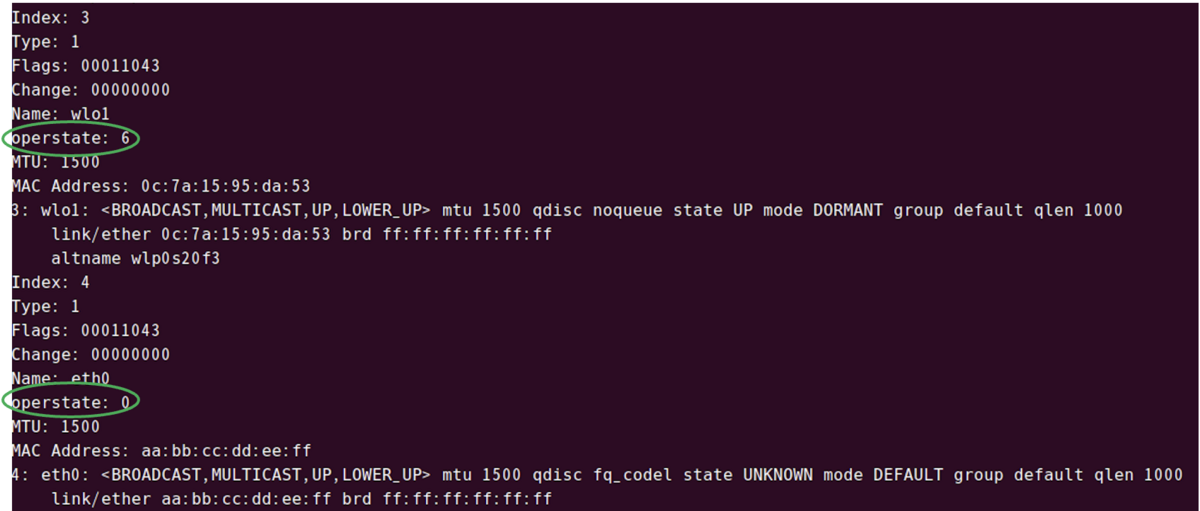
そこで今度は、Linuxカーネル内のどこの部分がnetlinkメッセージのこの部分に値を設定しているのかを調べた。
https://elixir.bootlin.com/linux/v6.6.6/source/net/core/rtnetlink.c#L1807
すると、net_device構造体のoperstateという変数が参照されているような記述が見つかったので、ドライバでその値を適切に設定するように変えた。
その結果、無事に自作ドライバと紐づくインターフェースのstateがUPという風に表示されるようになった。

処理を全て追いかけたわけではないが、この rtnl_fill_ifinfo という関数は、
- RTM_GETLINKメッセージを受け取った時のハンドラ関数
- net_deviceに関するイベント(register・open・close・chage state・異なるnamespaceへの移動など)が起きた際にnetlinkメッセージを作成する関数
から呼び出されていた。
さいごに
怪しい記述や間違っている箇所を見つけてくださった方がいれば、教えていただけると嬉しいです...
MikanOSにユーザースレッド風機能を実装
概要
初めに
このブログは以前書いたものを、2022 自作 OS Advent Calendar用に書き換えて再公開したものです。
当初は備忘録的な意味で書き殴っていたものであるため、非常に長くまとまりのない文章になってしまってすみません。
また勘違いをしていて間違った内容を書いているところがあるかもしれないので、気付いた方はご指摘をいただけると嬉しいです。
このブログの内容について
前回のブログでMikanOSにspinlockを実装したつもりであったが、勉強していくうちに、MikanOSはシングルスレッドなのでCPUで割り込み防止をするだけで排他制御が可能であることが分かった。
そしてMikanOSにはアプリケーションを並列処理で実行するための仕組みが備わっていないことも知った。
今回はそれを実現するためのユーザースレッドを実装した。
なお前回のブログに書いていた通り、自力で調べて実装までするのは難しいと感じたため、サイボウズ・ラボユースに応募してそこで取り組ませてもらうことにした。
labs.cybozu.co.jp
サイボウズ・ラボユースは、世界に通用する日本の若手エンジニアの発掘と育成を目指すことを目的に、学生の若手クリエイターに研究開発の機会を提供する場としてサイボウズ・ラボさんが開いてくだっさっている。
ここに採択されると、サイボウズ・ラボの方にメンターとしてついてもらって自分のしたい研究・開発に取り組むことができ、奨励金もいただくことができるという嘘みたいな本当の制度である。
訂正
記事内ではユーザスレッドを実装したという風に書いていますが、下にも書いているようにユーザースレッドというのは、システムコールを用いてユーザ側でスケジューリングを行うものである。
今回はスケジュール自体をカーネル側に任せているので、ユーザースレッド風機能という言い方がよいだろうか。
ユーザースレッドについて
スレッドとは
そもそもスレッドとはどういったものだろうか。
スレッドとプロセスの違いなども含めて説明しておきたいと思う。
簡単に述べると、
- プロセス:プロセスID,メモリ空間,コンテキストなどを独自に持つ実行単位
- スレッド:プロセスに紐づいている、メモリ空間をプロセスと共有するひとまとまりの命令処理
といった具合だろうか。
(おまけ)低レイヤの話 ~Linuxとの比較~|Goでの並行処理を徹底解剖!
なおこのブログにも書いてある通り、Linuxカーネル内部ではプロセスとスレッドはtask_struct構造体という共通のデータ構造で扱われている。
ユーザースレッド
ユーザースレッドとは、ユーザー空間上で生成されるスレッドのことである。
スケジューリングはライブラリ内のスレッドスケジューラが行う。
今回実現したユーザースレッドの機能と仕様
今回は、POSIXスレッドにおけるpthread_createとpthread_joinにあたる機能を実装した。
create関数は引数として、新スレッドに対応するapp_thread_t構造体へのポインタと新スレッドのエントリポイント関数のアドレス、その関数に渡す引数をとる。
pthread_createと違い、属性の指定はできない。
apps/app_thread.cpp
int app_thread_create(app_thread_t* t, void* f, int64_t data){ auto [ret, err] =SyscallThreadCreate((void *)f,data); t->task_id=ret; return 0; }
join関数は引数として待ち合わせたいスレッドに対応するapp_thread_t構造体へのポインタを引数として取る。
pthread_join関数ではpthread_t構造体そのものを引数として取るが、createと違う形にすることに特に意味はないと思ったので、join関数もポインタを引数にすることとした。
処理の中身は、指定したスレッドが終わっているかを無限ループで監視し続け、終わっていたらループを抜けるというものである。
int app_thread_join(app_thread_t *thread){ int64_t task_id=thread->task_id; while(1){ auto [ret, err]=SyscallTaskExist(task_id); if(ret==0){ break; } } return 0; }
スレッドのエントリポイント関数は、引数として64bitの値をとる。
実装に必要な前提知識
実装に必要な計算機科学やMikanOSについての前提知識をまとめる。
MikanOSにおけるマルチタスクの実現
MIkanOSを含む多くのOSにおいて、マルチタスクの実現はコンテキストを切り替えることによって行う。
スタックポインタや命令ポインタなどの値をそっくりすげ替えることで、CPUからすると命令を逐次実行しているだけにも関わらず、全く違う処理に飛ぶことができるのだ。
ただし、タスクを切り替える前の処理にもう一度戻ってこれるように、前のタスクにおけるスタックポインタや命令ポインタなどの値を保存しておく必要がある。
このようなデータや変数のまとまりのことをコンテキストと呼ぶ。
MikanOSのコンテキスト構造体を以下に示す。
コンテキストを切り替える際に値の保存と復帰が必要なレジスタを全て含んでいる。
struct TaskContext { uint64_t cr3, rip, rflags, reserved1; // offset 0x00 uint64_t cs, ss, fs, gs; // offset 0x20 uint64_t rax, rbx, rcx, rdx, rdi, rsi, rsp, rbp; // offset 0x40 uint64_t r8, r9, r10, r11, r12, r13, r14, r15; // offset 0x80 std::array<uint8_t, 512> fxsave_area; // offset 0xc0 } __attribute__((packed));
タスクの自動切り替えは、タイマーによって一定時間が来たら割り込みを行うような処理をして、その割り込みのハンドラでSwichTask関数を呼ぶことで実現している。
メモリ空間
MikanOSを始めとするx86-64の64bitモードで動くOSは、メモリ管理をページングによって行う必要がある。
ページングとは仮想記憶(仮想メモリ)の方式の一つで、メモリ領域をページと呼ばれる一定の大きさの領域に分割し、物理的なアドレス(番地)とは別に仮想的なアドレスを割り当てて管理する方式である。
ページング方式 - Wikipedia
x86_64におけるページング構造は、次のような階層を持っている。
この構造通りにメモリ上に階層ページング構造(ページテーブル等)を構築すれば、MMUがそれを辿ることで仮想メモリ-物理メモリ間の変換を行うことができる。

出典:
https://qiita.com/mopp/items/82bef23d0470de21b5d3
特権レベル3で動くアプリの呼び出しと復帰 (CallApp)
特権レベル3で動かすアプリの処理へ移行するためには、以下のことが必要である。
- 予めDPL(descriptor_privilege_level)=3を持つコードセグメントとデータセグメントを構築し、GDT(Grobal Descriptor Table)に登録しておく。
- アプリを呼び出す前に、アプリ用のスタック領域や引数受け渡し用の領域をアプリ用のアドレス空間に構築しておく。
アプリ用のページテーブルへのポインタをcr3レジスタに入れた上で、userビット1の領域をSetupPageMaps関数で確保することで、アプリ用のアドレス空間にアプリが使えるメモリ領域を作ることができる。
移行時の処理としては、
- OS用のスタック領域に、現在の各種レジスタの値を保存する。
- アプリ呼び出しの際に、セグメントレジスタであるCS・SSがそれぞれ先程登録したコードセグメント・データセグメントを指すようにする。
- rspを書き換えてスタックをアプリ用のものに変える。
- ripの値をアプリのエントリポイント関数のアドレスに書き換える。
上記の処理を行うことで、そのタスクにおいて権限レベル3でアプリが動き出す。
なお上記の内2-4のレジスタ書き換え処理は、スタックに適切な順番で値を積んだ後に、far returnを呼び出すことで実現している。
(権限が低いコードセグメントへのfar returnの場合、rip・csだけでなく、ss・rspもスタックから取り出される。)
この処理を行うのがCallApp関数である。
kernel/asmfunc.asm
global CallApp CallApp: ; int CallApp(int argc, char** argv, uint16_t ss, ; uint64_t rip, uint64_t rsp, uint64_t* os_stack_ptr); push rbx push rbp push r12 push r13 push r14 push r15 mov [r9], rsp ; OS 用のスタックポインタを保存 push rdx ; SS push r8 ; RSP add rdx, 8 push rdx ; CS push rcx ; RIP o64 retf ; アプリケーションが終了してもここには来ない
アプリを終了して特権レベル3から0に戻す処理には、システムコールを利用する。
通常のシステムコールは処理が終わるとsysret命令で呼び出し元の処理に戻る。
しかしアプリ終了システムコールは、処理の最後でスタックをアプリ用のものに切り替えたのち、ret命令を呼ぶ。
そうすることで、CallApp関数を呼んだOS側の処理に戻る。
CallApp関数がここへのreturnを呼ぶことはないので、CallApp関数呼び出し時のcall命令でスタックに積まれたripの値を、アプリ終了システムコールが利用するという形である。
(CallApp関数の最後のfar returnが呼ばれるときは、スタック(やその他レジスタ)がアプリ用のものになっていて、スタックに積まれた取り出すべきripの値はアプリのエントリポイントである。)
アプリケーションから画面への出力
アプリ上のprintf()関数等からターミナルへの出力を行うためには、write()システムコールが必要である。
Making sure you're not a bot!
(このようなドキュメントを見ていくことで、標準関数に必要な関数とその形式を調べることができる。)
MikanOSにおけるwrite()はapps/newlib_support.cppの中に実装されており、その実体はPutStringシステムコールを呼び出すことである。
PutStringシステムコールでは、指定されたファイルディスクリプタの番号に従って、適切な場所に文字列を送り込むことである。
(MikanOSにて実装されているのは、ターミナルへの出力およびコマンドのパイプライン上への出力である)
設計と実装
設計の背景と概要
プロセス
MikanOS上でタスクと呼ばれているものは、メモリ空間を別に持つためLinuxにおけるプロセスのようなものである。
ただしMikanOSではLinuxと違って、タスクをツリー構造ではなくリストとして管理しており、タスク同士の親子関係という概念も存在しない。
しかしスレッドを実装する上でどのプロセスのメモリ空間と紐づくスレッドかという情報をタスクに置いておく必要があるため、リスト構造となっているのとは別に親子関係を示すポインタを保持しておく。
スケジューリング
なお本来ユーザースレッドのスケジューリングはアプリ側のライブラリ内のスレッドスケジューラが行うものだが、今回はユーザースレッドも他のプロセスと同様にOSがスケジューリングを行うようにした。
メモリ空間
またMikanOSにおけるtaskはLinuxのプロセスのように、データやメモリ空間をそれぞれ独立して持つ。
一方ユーザースレッドは、親タスクや他のスレッドとメモリ空間を共有している必要がある。
ページング方式のメモリ管理において、メモリ空間を共有するということは、ページマップ(ページング構造)を共有するということである。
そのためスレッドは、親タスクが持つページング構造をそのまま利用するような実装にした。
追加したデータ構造
task、terminal、layer(画面に出力する平面の画像データ。複数重ね合わせることで、windowの重なりやマウスポインタなどを表現。)を繋ぐデータ構造を変更した。
元々の実装
- terminal-task
- layer-task
- (もちろんlayer-terminalも)
がそれぞれ1対1対応だった。
キーボードからの入力があった際に、アクティブな(一番上に来ていて入力を受け付けている)レイヤーと対応しているタスクに、入力された文字列を送信する仕組みをとっていた。
新しい実装
1つのターミナルに複数のタスクが紐づくようになり、layerとtaskが1対1対応ではなくなった。
そこで、
class Terminal {
//省略
uint64_t input_task_id=0;
//省略
};
このような変数を付け加えて、ターミナルの中のどのタスク(スレッド)から入力があったかを記録するようにした。
また、
- terminal-layer
間は1対1対応である。
そこで、
- layer->terminal ->task(input_task_idを持つもの)
というふうに辿ることで、入力を適切なタスクに送り届けるようにした。
システムコールの準備
ユーザースレッドは、アプリケーションからシステムコール呼び出しで作成される。
今回はスレッドを作成するシステムコールに加え、指定したタスクIDをもつタスクが存在するか調べるもの、アプリケーションが動くタスクにて使用しているCR3レジスタの値を返すもの、CPUの割り込み禁止/許可によって排他制御を実現するシステムコールを加えた。
apps/syscall.h
struct SyscallResult SyscallThreadCreate(void *f,uint64_t data); struct SyscallResult SyscallCR3toApp(); struct SyscallResult SyscallTaskExist(uint64_t task_id); struct SyscallResult SyscallIntrLock(); struct SyscallResult SyscallIntrUnlock();
スレッド生成処理の流れ
スレッド生成システムコールが呼び出されると、まずはthread_create関数が呼び出される。
そこから呼び出される関数ごとに、処理の流れを説明してゆく。
thread_create
- まずは空のタスクを生成して、タスク構造体に親子関係を記述する。
- その後、生成したタスクのコンテキスト構造体に各種設定をしてゆく。
- スレッドでは呼び出し元タスクとメモリ空間を共有するため、現在のcr3レジスタの値を取得して、それをそのまま新たなスレッドのコンテキスト構造体のcr3の値に設定する。
(システムコールによって処理がカーネル側に奪われた際も、cr3レジスタの値は変化しないようになっている。)
- ripにはexec_thread_funcのアドレスをセットし、引数を示すrdi、rsi、rdxに引数の値をセットする。
そして最後にこのスレッドをWakeupさせれば、ここまでで作成したタスクにCPU時間が割り振られるようになる。
このタスクが初めて実行される時、ripにセットしたexec_thread_func関数のアドレスから実行が始まる。
kernel/thread.cpp
uint64_t thread_create(ThreadFunc* f,int64_t data){ __asm__("cli"); Task* current=&(task_manager->CurrentTask()); Task* new_task=&(task_manager->NewTask()); __asm__("sti"); new_task->is_thread=true; new_task->parent_id=current->ID(); current->children_id.push_back(new_task->ID()); //ここでいろいろコピー const size_t stack_size = new_task->kDefaultKernelStackBytesOfThread / sizeof(new_task->stack_[0]); new_task->stack_.resize(stack_size); uint64_t stack_end = reinterpret_cast<uint64_t>(&new_task->stack_[stack_size]); memset(&(new_task->context_), 0, sizeof(new_task->context_)); new_task->context_.cr3 = GetCR3(); //printk("thread_create : cr3=%lx\n",new_task->context_.cr3); new_task->context_.rflags = 0x202; new_task->context_.cs = kKernelCS; new_task->context_.ss = kKernelSS; new_task->context_.rsp = (stack_end & ~0xflu) - 8; void (*etfunc)(ThreadFunc* ,u_int64_t,int64_t)=exec_thread_func; new_task->context_.rip = reinterpret_cast<uint64_t>(etfunc); new_task->context_.rdi = reinterpret_cast<uint64_t>(f); new_task->context_.rsi = new_task->ID(); new_task->context_.rdx = data; task_manager->Wakeup(new_task); return new_task->ID(); }
exec_thread_func
- まずstack_frame用のメモリ領域に、スレッド用のスタック領域を確保する。
具体的にはスタック領域として使用したいアドレスの範囲をSetupPageMaps関数渡すと、この関数がページング構造を設定してくれるので、その領域にアクセスすることが可能となる。
- その後、ファイルディスクリプタを親タスクと共有する。
これによって、親タスクと同じターミナルからの入出力が可能となる。
- デマンドページングによって使用可能なアドレスの範囲も親タスクと共有する。
- 最後に、CallAppforThreadを呼ぶ。
CallAppforThreadは、引数の数以外は CallApp関数と同じである。
戻ってきたら、その自分自身のタスクをスリープさせておく。
kernel/thread.cpp
void exec_thread_func(ThreadFunc* f,uint64_t task_id,int64_t data){ Task* child=task_manager->GetTaskFromID(task_id); Task* parent=task_manager->GetTaskFromID(child->parent_id); const int stack_size = 16 * 4096; num_of_thread++; LinearAddress4Level stack_frame_addr{0xffff'ffff'ffff'f000 - (stack_size)*(num_of_thread+1)}; // #@@range_end(increase_appstack) if (auto err = SetupPageMaps(stack_frame_addr, stack_size / 4096)) { printk("thread exec func : stack page map err\n"); while(1) __asm__("hlt"); return ; } for (int i = 0; i < parent->files_.size(); ++i) { child->Files().push_back(parent->files_[i]); } child->SetDPagingBegin(parent->DPagingBegin()); child->SetDPagingEnd(parent->DPagingEnd()); int ret = CallAppforThread(data, 3 << 3 | 3, reinterpret_cast<uint64_t>(f), stack_frame_addr.value + stack_size - 8, &(child->OSStackPointer())); while(1){ __asm__("cli"); task_manager->Sleep(task_id); } return; }
後処理
スレッドを呼び出したアプリケーションの終了時に、sleepしているはずの子スレッドを終了させるような実装にしている。
もしjoin忘れ等で親タスク終了時に子スレッドが走っていた際は、子スレッドをsleepさせるような実装にした。
難しかった点
今回の改造には様々な前提知識が必要なので、それを体系的に学ぶまでは難しいというより歯が立たない状態だった。
逆に、ラボユースのメンターの方とのミーティングの中でそれらの知識を手に入れて以降は、スムーズに設計と実装をすることができた。
QEMUが落ちてしまうバグ(おそらくトリプルフォールト?)に見舞われてデバッグに苦労した時期も一度あったが、printデバッグとGDBによるデバッグを組み合わせることで、原因を特定することができた。
(スレッド終了の待ち合わせができておらず、アプリ終了時に解放したメモリ領域にスレッドからアクセスしようとしていたのが原因だった。)
以下はMikanOSでのgdbデバッグのやり方をまとめたスライドである。
ゼロからのOS自作入門 輪読会 第7回 - Google スライド
マルチスレッドを用いたサンプルアプリケーション
実装したユーザースレッドの動作確認のために、3つのアプリケーションを作成した。
いずれも意図通り動作した。
テスト出力アプリ
2つのスレッドから異なるメッセージをターミナルに出力する。
2つのスレッドからの出力が、毎回違う順番で表示される様子


mikanos_thread1/apps/uthread1/uthread1.cpp at u_thread · yushoyamaguchi/mikanos_thread1 · GitHub
入出力アプリ
入力スレッドはキーボードからの入力があると、その数字をグローバル変数に設定する。
出力スレッドはグローバル変数の値を無限ループで表示し続ける。
このアプリで確認したいことは、
- 同ターミナルへの入出力を違うスレッドで行うことができること
- スレッド間でグローバル変数を共有できること
である。
mikanos_thread1/apps/uthread2/uthread2.cpp at u_thread · yushoyamaguchi/mikanos_thread1 · GitHub
ソートアプリ
int型配列を前後半2つに分けて、2つのスレッドでそれぞれマージソートした後、さらにマージする。
これもスレッド間で同じ配列を扱うテストである。
mikanos_thread1/apps/uthread3/uthread3.cpp at u_thread · yushoyamaguchi/mikanos_thread1 · GitHub
ソースコード
github.com
元のソースコードとの差分を見たい方は以下
github.com
謝辞
この実装は自分ひとりの力では絶対にできませんでした。
ラボユースでメンターをしてくださっている川合さんと様々なアドバイスをくださった内田さんという、ビッグなお二人の知恵をお借りしてで実現することができました。
ありがとうございました。
BuildしたFRRoutingをDockerコンテナで動作させ、BGPのオレオレPath Attributeを流す
- buildしたFRRoutingをDockerコンテナで動かす
- FRRoutingでbgpdを小改造し、自作path_attrをパケットに入れて運ぶ
- BGPあれこれ
- 動作確認
- おまけ : topotestsの動かし方
- Github
buildしたFRRoutingをDockerコンテナで動かす
imageのbuild
まず、FRR自体のbuildを行う。
Ubuntu 20.04 LTS — FRR latest documentation
例えばUbuntu20で動かす場合、このドキュメントに従えば良い。
次にそのバイナリをコンテナに組み込めるように、docker image をbuildする。
なお2回目以降のbuildに関しては、
sudo make install
だけでよい。
次に、そのバイナリを含んだdocker image をビルドする。
この部分に関しては、このシェルスクリプトを実行するだけで良い。
github.com
sudo bash path_to_frr/docker/alpine/build.sh
これが成功すれば、 frr:alpine-XXXXXX のような名前のdocker image が出来上がっているはずである。
コンテナ上でbgpdを動かす
docker run したのちそのコンテナのシェルに入り、以下のコマンドを実行する
sed -i -e 's/bgpd=no/bgpd=yes/g' /etc/frr/daemons /usr/lib/frr/frrinit.sh start
/etc/frr/daemonsにて、動かすデーモンの種類を指定する。
デフォルトでは多くが動かない設定となっている。
FRRoutingでbgpdを小改造し、自作path_attrをパケットに入れて運ぶ
eniyo0.hatenablog.com
この記事にならってオレオレPath Attribute を自作し、それをdockerコンテナ上で動かした。
Path Attributeの実装については、この記事を見ていただきたい。
実装が終わったらbuildして、前章の内容のとおりにdocker imageに組み込む。
コンテナを立ち上げてbgpdを起動し、次にvtysh(FRRのネットワーク設定用シェル)で以下のような設定をする。
(この設定は一例であり、必ずこの設定で正しく動くことを保証するものではない。)
conf te router bgp 3 no bgp ebgp-requires-policy yama_filter bgp router-id 3.3.3.3 neighbor 10.0.2.1 remote-as 2 ! address-family ipv4 unicast redistribute connected exit-address-family !
AS3にてAS2と接続する際の設定である。
yama_filterというのは、bgpのupdateメッセージのPath Attributeに自作path attrを挿入するためのコマンドである。
no bgp ebgp-requires-policy
については、次章のRoute Mapの項を見ていただきたい。
redistribute connected
については、次章のRedistributeの項を見ていただきたい。
BGPあれこれ
BGPの設定をする中で調べたBGP内の概念についていくつか説明する。
Route Map
Route Mapとは、特定のパケットやルートを定義した条件と、その時に実行される処理とで構成されるリストのことである。
経路フィルタや再配布などの条件設定に使われる。
FRRでは基本的にRoute Mapを用いて明示的に広報する/受け取る経路を指定する必要があるが、
no bgp ebgp-requires-policy
とすることで、すべてのフィルタを取り払って動かすこともできる。
Redistribute
BGP以外で手に入れた経路をbgpで流すための設定。
例えば、connectedである経路をBGPで広報したい場合は、
redistribute connected
という設定を入れる。
この情報は、Address Famillyごとに設定する。
Address Familly
MP-BGPでは、IPv4やIPv6の複数のプロトコルをサポートすることから、それぞれの経路情報を区別して管理するためのグループであるAddress Famillyを定義している。
以下のような種類がある。
Split Horizon
iBGPピアからの経路情報をiBGPピアに流さないことで、iBGPルートがループするのを防止する。
Route-Reflector
AS内の全ルータをフルメッシュでiBGP接続すると、張らなければいけないピア数が増えすぎる。
そこで、Route-Reflectorと複数のクライアントという関係を結び、eBGPルータは得た経路をRoute-Reflectorのみに流すようにする。
そうすることでクライアントは、Route-ReflectorとさえiBGPピアを張りさえすれば各経路を受け取ることができるようになる。
動作確認
自作Path Attributeを含むBGP updateメッセージのパケットをキャプチャした様子は以下である。
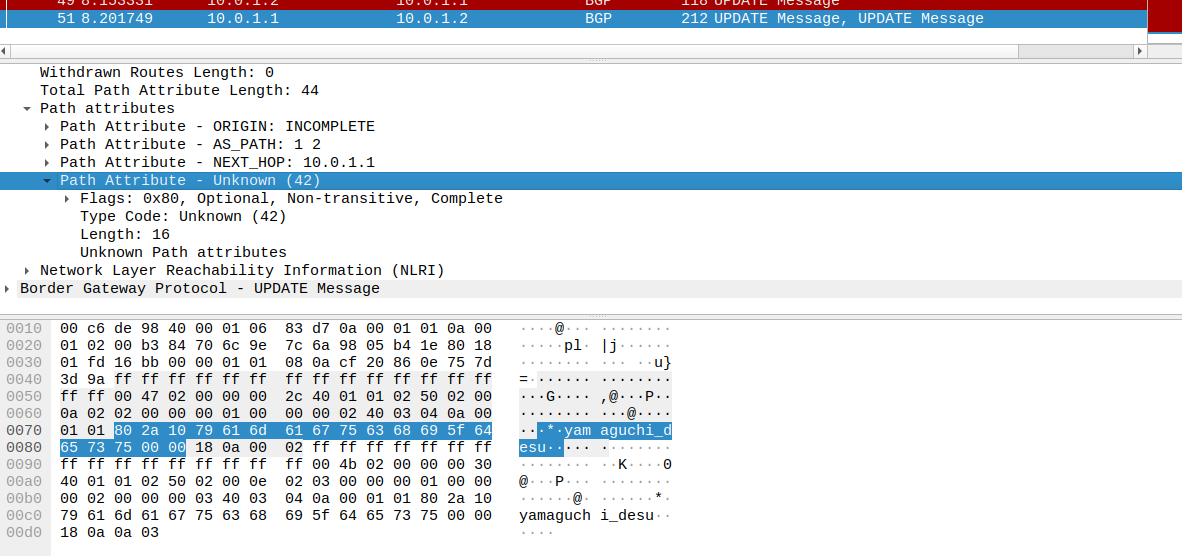
ただ単に文字列を含んでるだけであるが、確かにBGP updateメッセージに乗っている。
MikanOSのUSBブートの方法とmikanos-netの実機での通信実験
概要
MikanOSをUSBブートの方法についてまとめる。
また後半では、mikanos-netのe1000のデバイスドライバが実機でも使えることを確かめる実験を行っている様子を載せてている。
行った環境
Dellのデスクトップを使用した。
CPUはintel製で64ビットである。
(型番は忘れてしまった。)
そこにUSB端子でキーボードとマウスを接続した。
なおPanasonic製のノートパソコンであるLet't noteで試したところ、内臓キーボードとUSBマウスを認識しなかった。
方法
まずマシンのBIOS画面に入り、セキュアブートをOFFにしたのち、UEFIブートの優先順位のトップをUSBブートにする。
そして、USBメモリの適切な場所にブートローダ・カーネルコード・アプリのコードのバイナリを配置したのちマシンを起動すると、MikanOSが実機で立ち上がる。
コード修正
qiita.com
このサイトを参考に、2箇所の修正を行った。
エントリポイント
メモリマップを確認したところ、kernelのmain関数がロードされるアドレスが予約済みの領域だったため、Makefileを修正した。
kernel/Makefile
#LDFLAGS += --entry KernelMain -z norelro --image-base 0x100000 --static LDFLAGS += --entry KernelMain -z norelro --image-base 0x110000 --static
USBマウスの認識
上記のサイトを参考にして、以下の点の修正を行った。
詳細はリンクを見てほしい。
kernel/usb/memory.hpp
// [org] static const size_t kMemoryPoolSize = 4096 * 32 static const size_t kMemoryPoolSize = 4096 * 64;
USBメモリへのコピー
上記の点を修正してBuildしたら、次はその内容をUSBメモリに格納する。
一つ一つコマンドを打っていくと長くなるので、シェルスクリプトを利用した。
ゼロからのOS自作入門メモ: 実機で動かすためのメモzenn.dev
このシェルスクリプトは、こちらのブログを執筆されているmaeharinさんからいただいたものを改造して作った。(ありがとうございます。)
大まかな流れとしては、
- mkfsコマンドでUSBメモリにFATファイルシステムを構築する
- USBメモリをマウントする
- その中にカーネルコード・ブートローダ・アプリケーションのバイナリファイルをコピーしてくる
- アンマウントする
という流れである。
UEFIの仕様により、ブートローダは/EFI/BOOT/BOOTX64.EFIに配置することとする。
ゼロからのOS自作入門メモ: 第1章
#!/bin/bash set -ex # # usbを差し込んでdmsgコマンドを実行した結果、/dev/sda1になっていることを確認のうえ実行 #/path_to_mikanosのところは、自分の環境のものに置き換える # USB=/dev/sda1 KERNEL_ELF=/path_to_mikanos/mikanos/kernel/kernel.elf LOADER_EFI=$HOME/edk2/Build/MikanLoaderX64/DEBUG_CLANG38/X64/Loader.efi APPS_DIR_IN_DEV=/path_to_mikanos/mikanos/apps MNT_DIR=/mnt/usbmem umount $USB mkfs.fat $USB mkdir -p $MNT_DIR mount $USB $MNT_DIR mkdir -p $MNT_DIR/EFI/BOOT cp $KERNEL_ELF $MNT_DIR/kernel.elf cp $LOADER_EFI $MNT_DIR/EFI/BOOT/BOOTX64.EFI #アプリをすべてコピー for APP in $(ls $APPS_DIR_IN_DEV) do if [ -f "$APPS_DIR_IN_DEV/$APP/$APP" ] then cp "$APPS_DIR_IN_DEV/$APP/$APP" $MNT_DIR fi done umount $USB
mikanos-netを用いたUbuntuマシンとの通信の実験
MikanOSにNIC であるe1000のデバイスドライバとTCP/IPプロトコルを入れたものを、mikanos-netという名前で公開してくださっている方がいらっしゃる。
github.com
このコードを利用して、mikanos-net搭載のマシンとUbuntuマシン間で通信を行う実験を行った。
ソースコードの改変
PCIバスからNICを識別するところで、ベンダIDを指定する部分の処理を省いた。
この操作が必要であるかどうかは、どのマシンを用いて実験するかによると思う。
for (int i = 0; i < pci::num_device; ++i) { //if (pci::ReadVendorId(pci::devices[i]) != 0x8086 || pci::ReadDeviceId(pci::devices[i]) != 0x10d3) { if ( !(pci::devices[i].class_code.Match(0x02u, 0x00u, 0x00u))) { //変更箇所 continue; }
加えて、デバイスドライバ内の送信処理の中のbusy waitの部分にデバッグプリントを加えた。
空のwhile文をやめたのだが、なぜこれでうまくいったかは分かっていないが、最適化がかかってbusy waitの部分がバイナリから省かれたのかもしれない。
static ssize_t e1000_write(struct net_device *dev, const uint8_t *data, size_t len) { struct e1000 *adapter = (struct e1000 *)dev->priv; uint32_t tail = e1000_reg_read(adapter, E1000_TDT); struct tx_desc *desc = &adapter->tx_ring[tail]; desc->addr = (uintptr_t)data; desc->length = len; desc->status = 0; desc->cmd = (E1000_TXD_CMD_EOP | E1000_TXD_CMD_RS); debugf("%s: %u bytes data transmit", adapter->dev->name, desc->length); e1000_reg_write(adapter, E1000_TDT, (tail + 1) % TX_RING_SIZE); while(!(desc->status & 0x0f)) { // busy wait debugf("busy wait");//追加分:ここを抜くと固まる } return len; }


自作TCP/IPスタックをMikanOSへ移植
概要
Klab Expert Camp にて作った自作TCP/IPスタックをMikanOSに載せたので、その時のことを書いていく。
Klab Expert Camp
Klab Expert Camp は Klab株式会社さんが開催してくださっているインターンで、Linuxカーネル上で動作する自作TCP/IPスタックmicropsのコードを写経・穴埋めしながらTCP/IPについての理解を深めることができるイベントである。
3月に開催された第5回に参加してmicropsの再実装に取り組んだ。
micropsの実装について

上が、micropsの構成を図にしたものである。
本来TCP/IPスタックはOSのカーネル内で動いており、もちろんLinuxでも同じである。
そのLinux上のユーザ空間でプロトコルスタックを動かすために、少し工夫が必要がある。
具体的には、
- ユーザ空間からNICへアクセスすることはできないので、Ethernetデバイスをエミュレートするtapデバイスを利用する。tapデバイスはread/writeシステムコールによってユーザ空間からアクセスすることができる。
- パケットを受け取った際に割り込み処理を行う必要があるが、ユーザ空間のプログラムから割り込みを起こすことはできない。そこでmicropsではSIGNALを送ることで擬似割り込みを起こしている。
のような点が、カーネル内に実装されるTCP/IPスタックとmicropsの実装上の違いとして挙げられる。
またユーザ空間で動くmicropsにはシステムコールという概念は存在しないが、カーネル内のTCP/IPスタックのようにTCPやUDPの通信をPCB(Protocol Control Block)で管理しており、ソケット風のAPI関数を用いてmicropsで通信を行うプログラムを書くことができるようになっている。
micropsはすごく簡潔な実装がしてあるプロトコルスタックで、他にも紹介したい点が山ほどあるが、それについては自分が話すより、公開資料 を見ていただくほうがいいだろう。
TCP/IPスタックをMikanOSへ移植
micropsのTCP/IPスタックをMikanOSへ移植する際にすべきことはいくつかあるが、ここでは4つに分けて説明する。
なお、このTCP/IPスタックのMikanOS移植はmicrops作者の方が mikanos-net という名前のリポジトリで行っておられるので、今回はその実装を大いに参考にさせていただいた。
NICの準備とMikanOS用のデバイスドライバの実装
自分はMikanOSをQEMUで動かしていたので、QEMUのNICを準備してそのデバイスドライバを実装する必要があった。
今回はE1000という種類のNICを使用する。(E1000はIntelの NIC の一種のエミュレート バージョン)
NICの準備とデバイスドライバに関しては、mikanos-netの他に以下の一連のサイトの解説を参考にした。
qiita.com
実装の流れを端的に述べると
- NICデバイスとそのI/Oを扱うための特殊なレジスタを見つけ出す。
- 送受信の際のバッファ用のメモリ領域を用意する。
- 特殊レジスタを操作することによる、バッファ用領域を通したNICとの送受信を実現するための関数を用意する。
実装においては、NICの仕様に合うように様々な工夫をする必要があるが、ここではその説明は省略する。
是非上で示したサイトを参照していただきたい。
擬似割り込み処理をMikanOSの割り込みによって行うように変更
MikanOS(や他多くのOS)において、割り込みベクタ(番号)とそれに対応する割り込み記述子をIDT(割り込み記述子テーブル)という形で登録することによって割り込みが実現されている。
割り込み記述子には割り込みハンドラなどを登録する。
よってここで追加する処理は以下のようなものになる
kernel/interrupt.cpp
set_idt_entry(InterruptVector::kE1000, IntHandlerE1000);
- ハンドラの処理内容は、タスクに通知を送ること
kernel/interrupt.cpp
__attribute__((interrupt)) void IntHandlerE1000(InterruptFrame* frame) { task_manager->SendMessage(1, Message{Message::kInterruptE1000}); NotifyEndOfInterrupt(); }
- mainタスクはその通知を受け取ったら、NICからデータを読み込む関数を呼び出す
kernel/main.cpp
case Message::kInterruptE1000: e1000_intr(); break;
ソケット風API関数をシステムコール関数として登録
MikanOSのシステムコールは、アセンブリ言語のsyscall命令でSyscallEntry関数にシステムコール番号を渡すような設定をレジスタに入れておき、SyscallEntry関数で番号に応じた関数を呼び出すことによって行われている。
関数をシステムコールとして登録する際は、syscall_tableという関数ポインタ表にシステムコール番号とその関数へのポインタを登録すればよい。
具体的には、
apps/syscall.asm
define_syscall SocketOpen, 0x80000010 define_syscall SocketClose, 0x80000011 define_syscall SocketIOCTL, 0x80000012
apps/syscall.h
struct SyscallResult SyscallSocketOpen(int domain, int type, int protocol); struct SyscallResult SyscallSocketClose(int soc); struct SyscallResult SyscallSocketIOCTL(int soc, int req, void *arg);
kernel/syscall.cpp
SYSCALL(SocketOpen) { uint64_t ret = socketopen((int)arg1, (int)arg2, (int)arg3); return {ret, 0}; } SYSCALL(SocketClose) { struct socket *s = socketget((int)arg1); uint64_t ret = socketclose(s); return {ret, 0}; } SYSCALL(SocketIOCTL) { struct socket soc = {0, (int)arg1}; uint64_t ret = socketioctl(&soc, (int)arg2, (void *)arg3); return {ret, 0}; }
/* 0x10 */ syscall::SocketOpen, /* 0x11 */ syscall::SocketClose, /* 0x12 */ syscall::SocketIOCTL,
このようなソースコードを付け加えればよい。
その他のLinux特有システムコールを用いた関数(Timer関連,Thread関連等)を置き換え
micropsでは、pthread/mutexやtimerなどLinux系特有のシステムコールを用いた関数(POSIX標準関数など)を利用している。
当然自作OSのプログラムではそれらの関数を使用することはできないので、代わりとなる関数を自分で用意する必要がある。
下の例のように、POSIXの関数を同名でMikanOS内のタイマーを用いる関数として定義し直している。
net/port/mikanos.cpp
int gettimeofday(struct timeval *tv, void *tz) { unsigned long tick = timer_manager->CurrentTick(); tv->tv_sec = tick / kTimerFreq; tv->tv_usec = tick % kTimerFreq * (1000000 / kTimerFreq); return 0; }
mikados-netではmutex_lock/unlockなどのMikanOSに機能のない関数は空の関数として定義している。
ソースコードは以下の中にある。
https://github.com/yushoyamaguchi/mikanos_sub1github.com